
Methoden der Datenanalyse: Clustering
Clustering im echten Leben

Der Künstler Urs Wehrli ist dafür bekannt, dass er sehr gern aufräumt. Nichts ist vor ihm sicher, nicht mal Kandisky. Die Sendung mit der Maus erklärt das sehr schön - schauen Sie sich es gern im Video an!
Dieses “Aufräumen”, das Herr Wehrli da so gerne betreibt, ist letzten Endes eine besondere Form der Datenanalyse. Hier werden Entitäten in Cluster gruppiert, basierend auf ihren Merkmalen.
⚑ Quelle
Wesentliche Teile der folgenden Ausführungen sind aus dem Kurs “Machine Learning for Beginners” entnommen.
Was ist Clustering? Typische Anwendungen
Clustering ist ein Typ des Unüberwachten Lernens, der davon ausgeht, dass ein Datensatz unbeschriftet ist oder dass seine Eingaben nicht mit vordefinierten Ausgaben übereinstimmen. Es verwendet verschiedene Algorithmen, um unbeschriftete Daten zu durchsuchen und Gruppierungen entsprechend der Muster zu erstellen, die es in den Daten erkennt. Clustering ist sehr nützlich für die Datenexploration. Mal sehen, ob es helfen kann, Trends und Muster in der Art und Weise zu entdecken, wie das nigerianische Publikum Musik konsumiert.
✅ Nehmen Sie sich einen Moment Zeit, um über die Verwendungen von Clustering nachzudenken. Im wirklichen Leben tritt Clustering immer dann auf, wenn Sie einen Haufen Wäsche haben und die Kleidung Ihrer Familienmitglieder sortieren müssen. In der Datenwissenschaft tritt Clustering auf, wenn man die Vorlieben eines Benutzers analysiert oder die Merkmale eines ungelabelten Datensatzes bestimmen möchte. Clustering hilft gewissermaßen dabei, aus dem Chaos Sinn zu machen, wie bei einer Sockenschublade.
In einem professionellen Umfeld kann Clustering verwendet werden, um Dinge wie Marktsegmentierung festzulegen, zum Beispiel um herauszufinden, welche Altersgruppen welche Artikel kaufen. Eine weitere Verwendung wäre die Anomalieerkennung, vielleicht um Betrug in einem Datensatz von Kreditkartentransaktionen zu erkennen. Oder Sie könnten Clustering verwenden, um Tumore in einer Reihe von medizinischen Scans zu bestimmen.
✅ Denken Sie einen Moment darüber nach, wie Sie Clustering bereits in einem Banken-, E-Commerce- oder Geschäftsumfeld erlebt haben könnten.
Alternativ könnten Sie Clustering zur Gruppierung von Suchergebnissen verwenden - nach Einkaufslinks, Bildern oder Bewertungen zum Beispiel. Clustering ist nützlich, wenn Sie einen großen Datensatz haben, den Sie reduzieren und auf dem Sie eine genauere Analyse durchführen möchten, sodass die Technik verwendet werden kann, um Daten zu lernen, bevor andere Modelle erstellt werden.
✅ Sobald Ihre Daten in Clustern organisiert sind, weisen Sie ihnen eine Cluster-ID zu, und diese Technik kann nützlich sein, um die Privatsphäre eines Datensatzes zu bewahren; Sie können sich stattdessen auf einen Datenpunkt durch seine Cluster-ID beziehen, anstatt auf offenere identifizierbare Daten. Können Sie sich andere Gründe vorstellen, warum Sie sich auf eine Cluster-ID anstelle anderer Elemente des Clusters beziehen würden, um ihn zu identifizieren?
Clustering-Algorithmen

Es gibt über 100 Clustering-Algorithmen, und ihre Verwendung hängt von der Beschaffenheit der vorliegenden Daten und Ihrem Anwendungsfall ab. Scikit-learn bietet eine große Auswahl an Methoden zur Durchführung von Clustering an. Das Bild oben zeigt, wie verschiedene Algorithmen (–> Spalten) auf verschiedene zweidimensionale Datensätze reagieren (–> Zeilen) und diese jeweils in Cluster (–> Farben) einteilen. Schon aus der Grafik können Sie erkennen, das manche Algorithmen aufgrund ihrer Grundannahmen mehr oder weniger gut für bestimmte Probleme geeignet sind. Details dazu können Sie in Grundlagenkursen zu Maschinellem Lernen, konkret zu sogenannten unüberwachten Lernverfahren erfahren. Für einen schnellen Überblick ist die Scikit-learn Dokumentation ebenfalls hervorragend geeignet.
Definition: Unüberwachte Lernverfahren gehören zu den Algorithmen des Maschinellen Lernens. Es handelt sich um Verfahren, bei denen ein Datensatz ohne spezielle Zielvariable analysisert wird und der Algorithms selbstständig auffällige Muster im Datensatz identifiziert.
Lassen Sie uns einige der wichtigsten Algorithmen bzw. Kategorien von Algorithmen hier kurz kennenlernen: hierarchisches und Zentroid-Clustering sind in der alltäglichen Praxis des Data Scientists die einfachsten und gängigsten Tools.
Beide Verfahren unterscheiden sich ganz wesentlich durch ihren Output (siehe Abbildung oben): hierarchisches Clustering erstellt einen Baum von Ähnlichkeiten zwischen den Punkten, anhand dessen die Struktur des gesamten Datensatzes interpretiert werden kann. Dafür liefert die Methode jedoch keine direkte Zuweisung zu Clustern. Diese muss manuell durch geeignetes “Abschneiden” der Teilbäume erfolgen. Zentroid-basierte Methoden hingegen erstellen lediglich eine Zuordnung zu Clustern, nachdem der Parameter $k$ vom Data Scientist vorgegeben wurde.
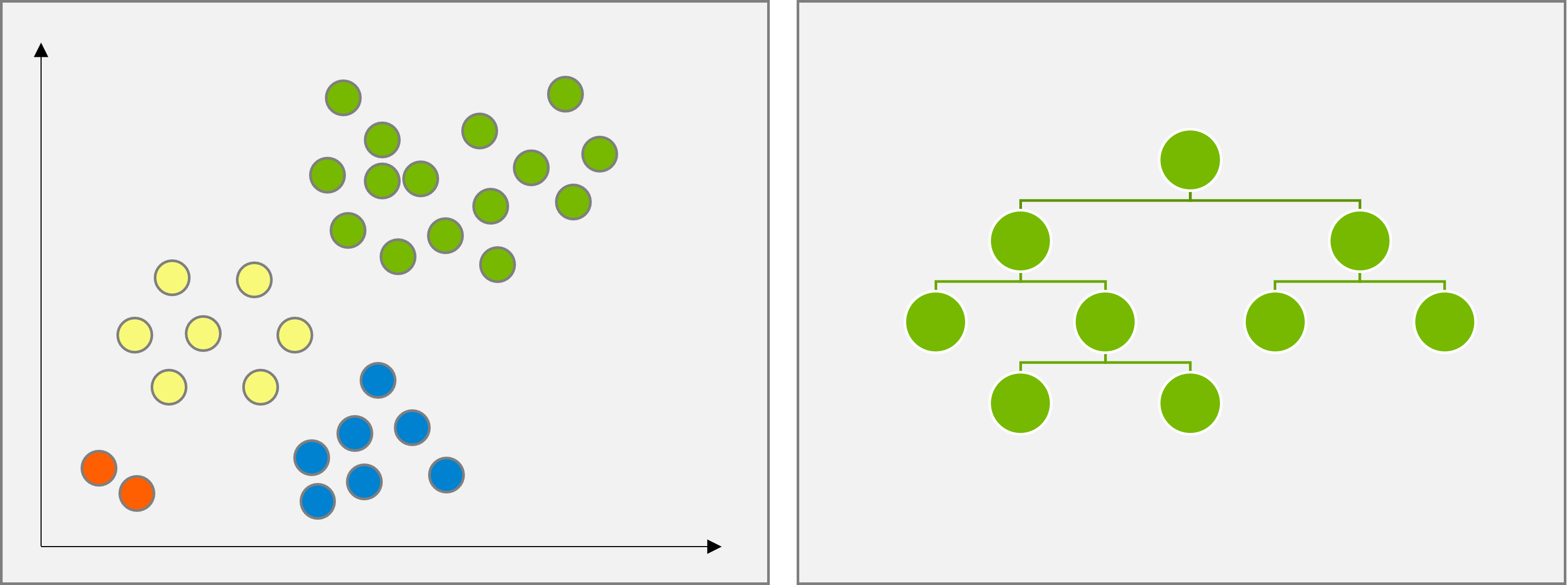
Hierarchisches Clustering
Hierarchische Clustering-Verfahren bilden Cluster aus Objekten, die zueinander eine geringere Distanz (oder umgekehrt: höhere Ähnlichkeit) aufweisen als zu den Objekten anderer Cluster. Man kann die Verfahren nach ihrer Berechnungsvorschrift unterscheiden in zwei Gruppen:
- divisive Clusterverfahren („Top-down-Verfahren“), in denen zunächst alle Objekte als zu einem Cluster gehörig betrachtet und dann schrittweise die bereits gebildeten Cluster in immer kleinere Cluster aufgeteilt werden, bis jeder Cluster nur noch aus einem Objekt besteht, sowie
- agglomerative Clusterverfahren („Bottom-up-Verfahren“)), in denen zunächst jedes Objekt einen Cluster bildet und dann schrittweise die bereits gebildeten Cluster zu immer größeren zusammengefasst werden, bis alle Objekte zu einem Cluster gehören.
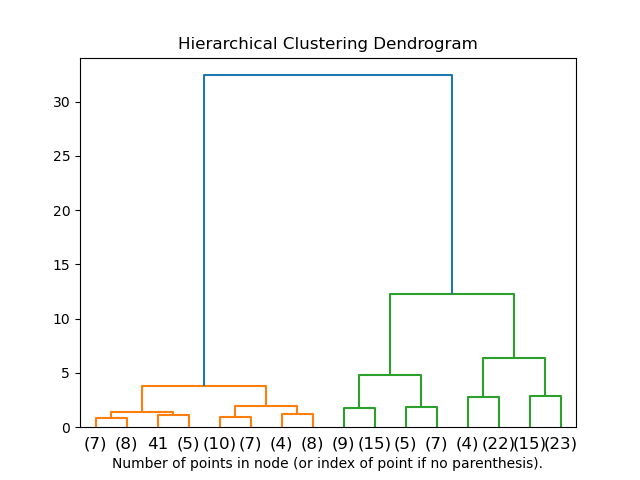
In beiden Fällen lässt sich das finale Ergebnis als hierarchische Struktur (Baum, Dendrogramm) darstellen.
Aufgabe: Studieren Sie das exemplarische Dendrogramm in der Abbildung oben. Überlegen Sie, was Sie aus der Struktur des Baumes über die Daten erfahren können.
Lösung: Das Dendrogramm zeigt zwei große Teilbäume, die durch sehr lange Kanten miteinander verbunden sind. Innerhalb der Teilbäume sind die Kanten eher kurz (im roten Teilbaum noch deutlicher als im grünen). Daraus lässt sich interpretieren, dass es zwei klare Cluster in den Daten gibt, die intern relativ homogen sind.
Für das hierarchische Clustering gibt es viele algorithmische Varianten, die sich unterscheiden durch die Wahl des konkreten Abstandsmaßes oder die Art, wie der Abstand zwischen zwei Gruppen von Punkten bestimmt wird. Studieren Sie die mathematischen Details der Algorithmengruppe in der Dokumentation von Scikit Learn zu hierarchischem Clustering.
Zentroid-Clustering
Dieses Vorgehen erfordert die Wahl von $k$, der Anzahl der zu bildenden Cluster, woraufhin der Algorithmus den Mittelpunkt eines Clusters bestimmt und Daten um diesen zentralen Punkt (das Zentroid) sammelt. Dies wird für alle $k$ Cluster durchgeführt, wobei üblicherweise Maße wie die Kompaktheit der Cluster und der Abstand zwischen Clustern optimiert wird.
K-Means-Clustering ist mit Abstand die beliebteste Version des Zentroid-Clustering. Studieren Sie die mathematischen Details des Algorithmus in der K-Means Dokumentation von Scikit Learn.
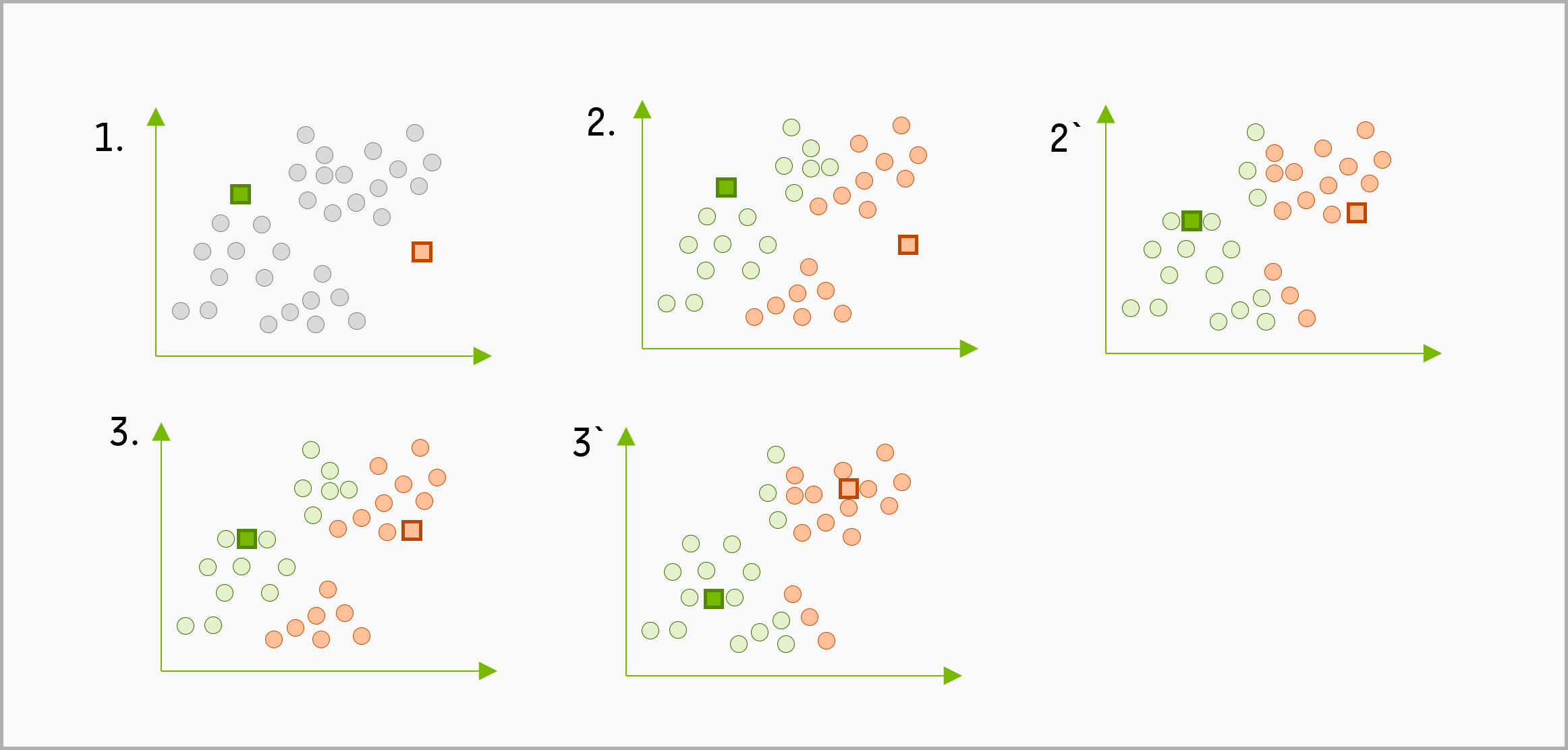
Weitere Clustering-Algorithmen
Über diese beiden bekannten Verfahren hinaus gibt es noch weitere Cluster-Methoden:
-
Verteilungsbasiertes Clustering. Basierend auf statistischer Modellierung konzentriert sich das verteilungsbasierte Clustering darauf, die Wahrscheinlichkeit zu bestimmen, dass ein Datenpunkt zu einem Cluster gehört, und ordnet ihn entsprechend zu. Gaußsche Mischmethoden (Gaussian Mixture Models) gehören zu diesem Typ.
-
Dichtebasiertes Clustering. Datenpunkte werden Clustern zugeordnet, basierend auf ihrer Dichte oder ihrem Gruppieren umeinander. Datenpunkte, die weit von der Gruppe entfernt sind, gelten als Ausreißer oder Rauschen. DBSCAN, Mean-Shift und OPTICS gehören zu diesem Clusteringtyp.
-
Gitterbasiertes Clustering. Für mehrdimensionale Datensätze wird ein Raster erstellt und die Daten werden auf die Zellen des Rasters aufgeteilt, wodurch Cluster erstellt werden.
⚑ Quelle
Quelle
Diese Lektion ist in Teilen angelehnt an den Kurs “Machine Learning for Beginners”.